
AI subscriptions are on borrowed time
Token prices are falling but your AI bill won't


On April 21, Anthropic quietly pulled Claude Code from its $20 Pro plan. No prior announcement. They’ve just placed a red X on the pricing page and a rewritten support document — long story short, Claude Code temporarily ceased to be available on the Pro plan and became only available on the Max subscription.
When people noticed, Anthropic’s head of growth said it was a small test affecting about 2% of new signups. Maybe. I’m not interested in conspiracy theories. Whether it stays or is reverted is irrelevant. This still looks to me like them testing the waters for a policy change already underway.
And it’s not just Anthropic. One day earlier, on April 20, GitHub announced it was pausing new signups for Copilot Pro, Pro+, and Student plans, tightening usage limits, and removing Opus models from the Pro tier. Their stated rationale: “agentic workflows have fundamentally changed Copilot’s compute demands... it’s now common for a handful of requests to incur costs that exceed the plan price.”
The fact is, your $20 a month was never really $20. Ditto for the $200 Max version. For two years, AI labs have been selling flat-rate subscriptions at prices far below the actual compute they consume. As Ed Zitron wrote: “Anthropic’s subscription plans charge far less than the book value of tokens consumed, sometimes by a factor of ten or more.”
That means: you paid $20, but you really burned through compute that cost them $50, $100, sometimes more. The difference was financed by venture capital. The bet is: grab the market now, figure out margins later.
You could argue it’s a typical Silicon Valley playbook. We’ve seen it before with Amazon, we’ve seen it with Uber, and plenty of other companies. All with Peter Thiel's acolytes chanting in the background: Competition is for losers, monopoly is the goal.
And we have historical proof that it works.
Or does it?
The curve ahead
Even as labs subsidize subscriptions, the underlying cost of generating a token has been falling at an impressive rate.
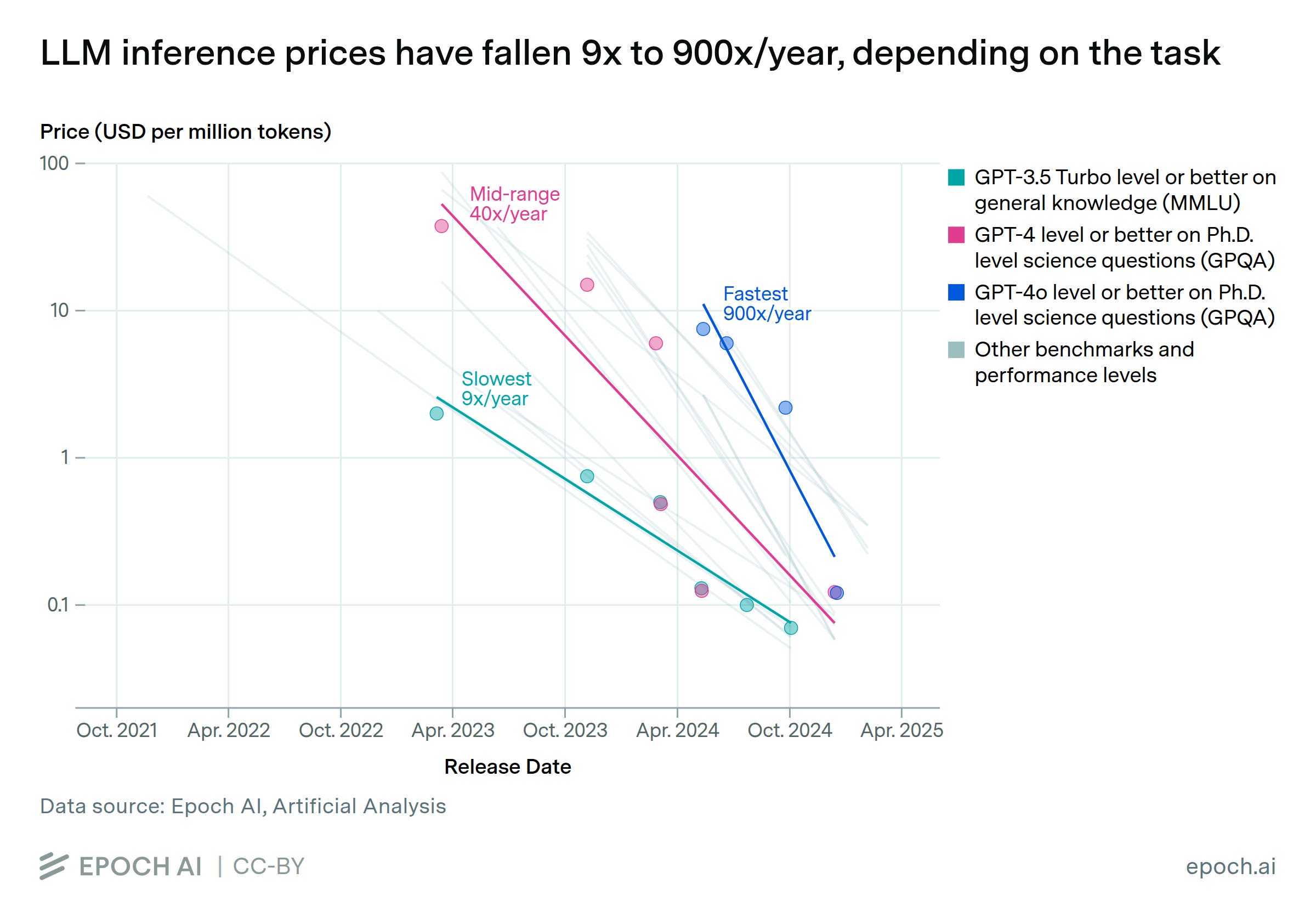
GPT-4 launched in March 2023 at $30 per million input tokens and $60 per million output tokens. Today, GPT-5.4 delivers vastly better performance at $2.50 and $15, respectively. That's roughly a 12x reduction in input costs and 4x in output costs in three years at the flagship tier — and far more if you compare on fixed capability.
Claude Opus 4.6, priced at $5/$25, costs a third of what Claude 3 Opus did two years ago ($15/$75).
Gemini 2.0 Flash hit $0.10/$0.40 in late 2024 — prices that would have sounded absurd even eighteen months earlier. The curve bends everywhere you look (for comparison: GPT 3.5 — $0.50/$1.50 — being inferior to Gemini 2 Flash overall, even in pure text use cases).
The reductions aren’t just coming from better hardware, though. Andrej Karpathy recently retrained a GPT-2 grade model for $73 — the same model that cost OpenAI around $43,000 to train in 2019. That’s a 600x reduction in seven years, falling roughly 2.5x every single year. Part of it is hardware (H100s beat TPU v3s). Part of it is software (FlashAttention, fp8 training, better optimizers). But a huge part is just algorithmic progress — we’ve figured out how to do the same thing with far less compute.
“Past performance does not guarantee future results.” Got it.
This is nonetheless reminiscent of other historical price curves. Take the lithium-ion battery cost chart. The inflation-adjusted drop in the costs of lithium-ion batteries over the last 3 decades is mindblowing — ~99% over that period of time. A drop - mind you! - that enabled reinvention and mass production of electric vehicles and the growth of what is estimated to be a $1.6 trillion industry. (And I’ll completely ignore the far bigger impact it had on the consumer electronics industry at large.)
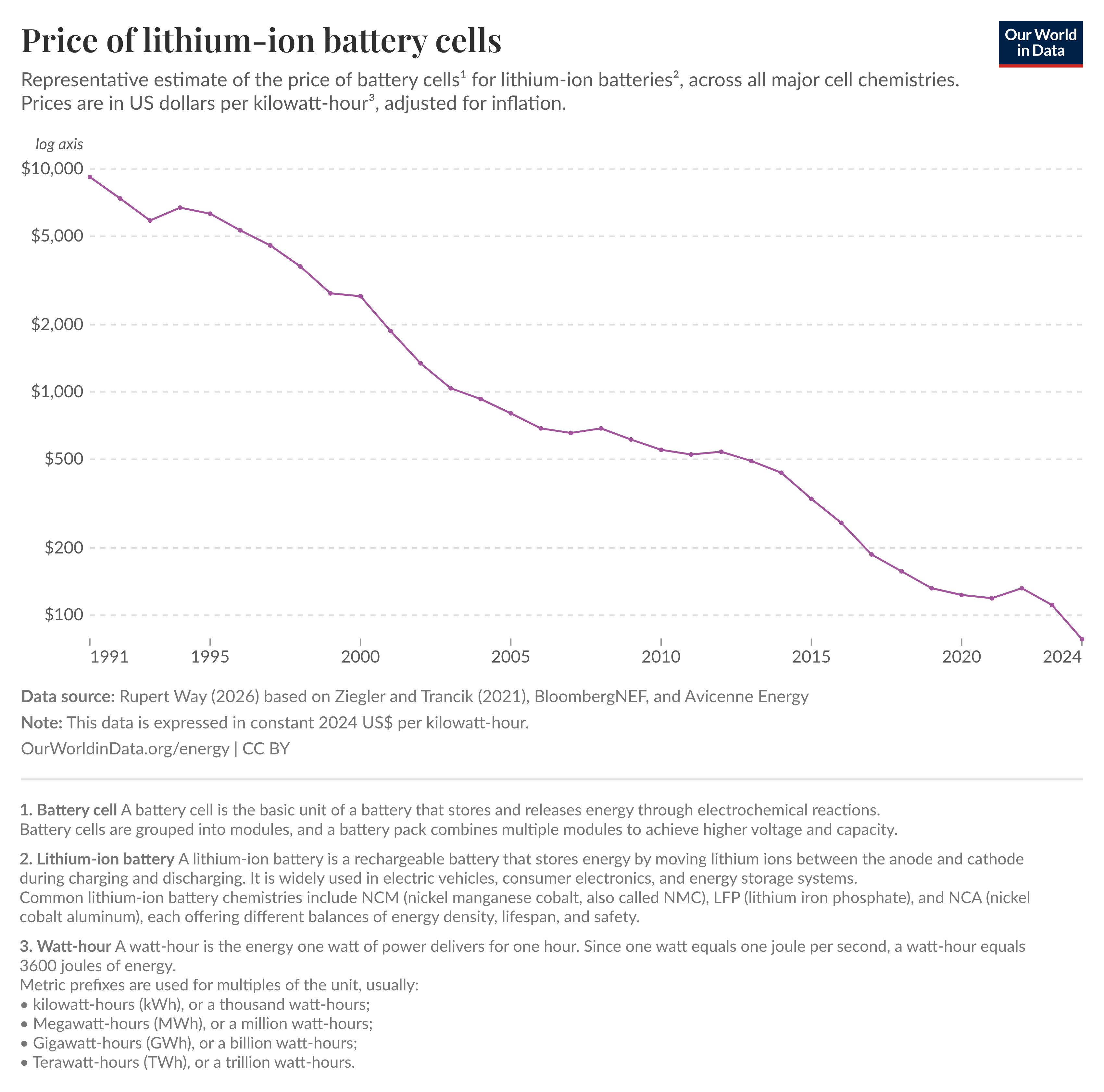
If this is not a textbook example of Jevons Paradox, I don’t know what is.
The unit economics
The Silicon Valley playbook mentioned earlier is not a clean parallel, though. Amazon was unprofitable for nine years and didn’t generate meaningful profits for closer to twenty. But Amazon sold books at roughly cost plus margin. Its losses came from warehouses, logistics, infrastructure — fixed costs that paid off once they were built. When Amazon got more popular, its unit economics improved.
What are the unit economics here?
Every token you generate costs the lab money, today, in electricity and GPU time. When more people use Claude, Anthropic bleeds faster. The subsidy isn’t a one-time investment that pays dividends later. It’s a tap. Actually, more of a firehose. Turning it off is the only way to stop the bleeding.
And the labs are starting to turn it off. Here are some examples:
In February, Anthropic introduced Fast Mode — 2.5x faster inference at 6x the standard rate. Same model, same capabilities, you’re paying a premium to skip the queue.
In March, they started throttling peak-hour usage across subscription tiers.
OpenAI runs its own version with “flex processing” — cheaper if you’re willing to wait.
These are pricing tweaks, not new features. Compute is scarce, and subsidies end. The price you pay will depend on when you use it, how fast you need it, and how much leverage the lab still has.
Here’s the twist. Even as the price of a token keeps collapsing, the bill is going up. How so? Well, ask yourself - with all these token prices falling so rapidly — are you paying less for AI subscriptions today than 2 years ago?
Enterprise LLM spend doubled in six months last year while per-token costs plummeted (did I mention Jevons Paradox already?). Agentic workflows burn 5 to 30 times more tokens per task than a simple chatbot (tool calls, multi-step reasoning, orchestrations, and so on). That’s why unit cost falls while at the same time the total cost explodes.
What comes next
Eventually, the underlying cost of a token will drop to a level where no subsidy is necessary. Depending on the source, the token costs fall at a rate between 2.5x (Karpathy example) and 10x (Epoch AI) per year.
Nvidia’s near-monopoly will also erode as AMD, Google’s TPUs, and Amazon’s Trainium chips take share at the infrastructure layer. The margins that Nvidia has today are just too outrageous to ignore. Competition at every layer will push prices toward the real cost of electricity and silicon, not the VC-subsidized numbers we’re seeing today.
This is, not coincidentally, what Sam Altman told the US Senate in May 2025:
”Eventually the cost of intelligence, the cost of AI will converge to the cost of energy and it’ll be how much you can have. The abundance of it will be limited by the abundance of energy.”
But between now and then, there’s a bill to be paid. The labs spent hundreds of billions acquiring users at a loss. They have to make that back. And the people paying it — whether through removed features, peak surcharges, or tiered pricing — are you.
So what does this mean if you’re building on any of this?
The price you see today is not the real economic price. It is whatever the lab currently wants you to believe the product costs. It will change, probably not in your favor, probably sooner than you think. Per-token pricing, peak surcharges, and tiered inference are the future. Anyone betting on labs absorbing the difference between subscription prices and real compute costs might be heading toward a nasty wake-up call in the short-term future.
I am ultimately an optimist. And few things show such predictable and consistent price drops as technology entering the mass market. But first, it’s going to get worse before it gets better.
Brace yourself.